
") Beim (wohl umstrittenen) Online-Anbieter Dr. Ansay gab es ein fettes Datenleck. Es ließen sich Rezepte für Cannabis-Produkte über die Suchmaschinen Bing und DuckDuckGo abrufen. Der Betreiber hat den Sachverhalt eingeräumt, sucht die Schuld aber bei den Suchmaschinen, die die Dateien „illegaler Weise“ indexiert haben und droht wohl mit rechtlichen Schritten.
Beim (wohl umstrittenen) Online-Anbieter Dr. Ansay gab es ein fettes Datenleck. Es ließen sich Rezepte für Cannabis-Produkte über die Suchmaschinen Bing und DuckDuckGo abrufen. Der Betreiber hat den Sachverhalt eingeräumt, sucht die Schuld aber bei den Suchmaschinen, die die Dateien „illegaler Weise“ indexiert haben und droht wohl mit rechtlichen Schritten.
Kleiner Rückblick auf Dr. Ansay
Auf dem Online-Portal Dr.Ansay lassen sich Krankschreibungen, aber auch Rezepte von Patienten ordern. Bei der Kombination Dr. Ansay und Rezepte könnte der Eindruck entstehen, dass da ein Mediziner das Portal betreibt. Aber ein Blick ins Impressum der Webseite offenbart (für mich überraschend), dass Dr. jur. Can Ansay als beauftragter Rechtsanwalt für den Inhalt der Seite verantwortlich zeichnet. Der Sitz der als Ltd. fungierenden Unternehmung ist Malta, als weitere Adresse wird Hamburg angegeben.
Beim Portal hat es ein fettes Datenleck gegeben: Ein Verzeichnis mit generierten PDF-Dateien zu Canabis-Rezepten war wohl frei per Internet erreichbar und wurde von der Suchmaschine Bing indexiert.
Die Suchmaschine DuckDuckGo greift auf diese Daten zu und lieferte demnach auch Treffer auf die betreffenden PDF-Dokument mit Canabis-Rezepten. Dritte konnten also sehen, wer Rezepte für Cannabis für medizinische Zwecke auf der Plattform eingereicht hatte, welche Krankenkasse zuständig ist und wo die Person wohnt.
Datenlecks sollten, speziell in diesem sensiblen Bereich nicht vorkommen, auszuschließen ist das nicht. Nachdem der Fehler bekannt wurde, hat der Betreiber den Ordner wieder geschützt. PDF-Dateien mit Rezepten sind nicht mehr auffindbar. Aber die Metadaten der Rezepte waren bzw. sind weiterhin per Suchmaschinen (Bing, DuckDuckGo) und Microsoft Copilot abrufbar.
Ich hatte über dieses Datenleck im Blog-Beitrag Autsch: Datenleck bei Dr. Ansay, Cannabis-Rezepte in DuckDuckGo sichtbar über die Details berichtet und auch etwas zur Plattform geschrieben. Ob dort Cannabis-Rezepte von Ärzten verordnet werden, interessiert in diesem Kontext weniger – und da habe ich keine Probleme mit. Dass ein Datenleck aufgetreten ist, bleibt weniger schön, ist aber passiert.
Unternehmen, die gut mit so etwas umgehen, arbeitet man so etwas auf. Ich erwähne in diesem Kontext den Beitrag Datenschutz-GAU bei Stay Informed Kindergarten-App, wo deren Datenschutzbeauftragter mich kontaktierte und weitere Informationen bereitstellte. Dort war das Bemühen, den Fall umfassend aufzubereiten, erkennbar.
Stellungnahme auf dransay.com und Details
Von Dr. Ansay liegt jetzt auch eine Reaktion vor. In diesem Kommentar hat ein Leser auf die Stellungnahme Datenleck vom 14.05.2024 verlinkt (danke dafür).
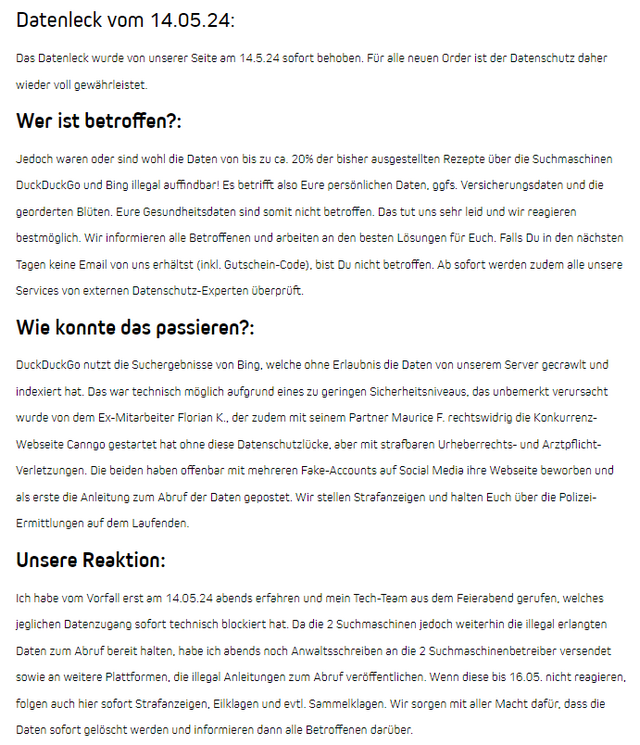 Hier die relevanten Angaben in Kurzform aus dem Dokument (siehe folgender Screenshot) herausgezogen und bewertet:
Hier die relevanten Angaben in Kurzform aus dem Dokument (siehe folgender Screenshot) herausgezogen und bewertet:
- Das Datenleck wurde (wohl nach Bekanntwerden) von Seiten des Betreibers am 14.5.24 behoben. Wie lange der betreffende Ordner mit den PDF-Dateien offen zur Indexierung im Internet erreichbar war, wird nicht mitgeteilt.
- Laut der Plattform Dr. Ansay seien nur 20 Prozent der bisher ausgestellten Rezepte über die Suchmaschinen DuckDuckGo und Bing auffindbar. Kann ich nicht widerlegen oder bestätigen.
In einem eigenen Absatz versucht der Betreiber zu relativieren – was aber zumindest vom Streisand Effekt sehr in die Hose gehen dürfte. Hier der betreffende Text, den ich mal zur Dokumentation herausziehe:
DuckDuckGo nutzt die Suchergebnisse von Bing, welche ohne Erlaubnis die Daten von unserem Server gecrawlt und indexiert hat. Das war technisch möglich aufgrund eines zu geringen Sicherheitsniveaus, das unbemerkt verursacht wurde von dem Ex-Mitarbeiter Florian K.,
der zudem mit seinem Partner Maurice F. rechtswidrig die Konkurrenz-Webseite Canngo gestartet hat ohne diese Datenschutzlücke, aber mit strafbaren Urheberrechts- und Arztpflicht-Verletzungen. Die beiden haben offenbar mit mehreren Fake-Accounts auf Social Media ihre Webseite beworben und als erste die Anleitung zum Abruf der Daten gepostet. Wir stellen Strafanzeigen und halten Euch über die Polizei-Ermittlungen auf dem Laufenden.
Dröseln wir doch mal die Aussage, die ich auf zwei Absätze gesplittet habe, auf. Die Aussage, dass die Rezepte illegal in den Suchmaschinen gelistet würden, und ohne Erlaubnis des Unternehmen gecrawlt wurden, ist meiner Meinung nach Bullshit vom Feinsten. Der Verantwortliche auf dransay.com ist zwar Jurist (Dr. Jur), sollte sich aber soweit über die Technik informieren, dass er zumindest weiß, dass Suchmaschinen-Crawler über eine robots.txt ausgeschlossen werden können, bevor er solche Aussagen trifft.
Die Aussage über den Ex-Mitarbeiter ist meiner Meinung nach eine Nebelkerze, die mit dem Datenschutzvorfall nichts zu tun hat. Die Strafanzeige in diesem Zusammenhang ist Nebelkerze Nummer 2, was den DSGVO-Vorfall betrifft – der Start einer angeblichen Konkurrenz-Webseite interessiert in diesem Kontext nicht. Der Fehler wurde beim Betreiber gemacht – und es ist ein besonders schwerer Datenschutzvorfall nach DSGVO, da besonders sensitive Daten über medizinische Sachverhalte von Patienten betroffen sind.
Schuld sind die Anderen
Fehler können passieren – das Unternehmen könnte dazu stehen. Nun versucht der Betreiber die vermeintliche „Schuld“ auf Ex-Mitarbeiter sowie die Suchmaschinen abzuwälzen und stellt sogar Strafanzeige. Auf elevated.city hat jemand die Schreiben des CEO und Juristen Dr. Ansary an Microsoft und DuckDuckGo veröffentlicht – die dort ausgesprochenen Drohungen gegenüber Redmond sind lachhaft (Ansary will Strafanzeige stellen, wenn die Suchergebnisse nicht sofort entfernt werden).
Der Streisand-Effekt sowie §203 a ff. werfen nun ihre Schatten voraus. Durch die Strafanzeige wird ein Verfahren bei der Staatsanwaltschaft angestoßen. Je nach Staatsanwaltschaft kann das eingestellt oder verfolgt werden. Der Vorwurf des „Ausspähens von Daten“ dürfte aber bei einer Suchmaschine eher – auch mit arger Ausdehnung des Rechts – nicht zu halten sein.
Inzwischen haben auch Golem und heise den Sachverhalt in separaten Artikeln behandelt. Interessant fand ich dort die Information aus der Apothekerzeitung, dass der Betreiber der Plattform bereits eine einstweilige Verfügung der Wettbewerbszentrale für COVID 19 Online-Testzertifikate erhalten hatte.
Was kann man tun?
Was können und sollten Betroffene tun? Als erstes eine DSGVO-Auskunft beim Unternehmen anfordern. Dann eine Meldung an die Datenschutzaufsicht absetzen und sich über den DSGVO-Vorfall beschweren. Und ggf. einen Anwalt, der sich mit Datenschutzrecht auskennt, kontaktieren, um die Frage eines Schadensersatzes zu klären (hier hat ein RA ein paar Details dazu veröffentlicht).
Ich habe inzwischen Beschwerde beim Hamburgischen Beauftragten für Datenschutz und Informationsfreiheit wegen des Vorfalls eingereicht.
Schlechte Reaktion, wird zum Normalfall
Mich erinnert der obige Fall an das Bauhaus-Thema (Datenleck beim Bauhaus-Shop legte Bestellungen von Plus Card-Inhabern offen). Dort hatte ich eine Entdeckung eines Lesers gemeldet, die Leute haben die Schwachstelle geschlossen, aber vergessen, die Daten in Bing.com löschen zu lassen (auf meine zweite Eingabe wurde das auch nachgeholt).
Absolut ein „geht gar nicht“ ist in meinen Augen der Versuch des Betreibers der Plattform, „die Schuld“ anderen zuzuschieben. Hier kann man nur hoffen, dass die unter der Rubrik „Was kann man tun?“ skizzierten Maßnahmen empfindlich greifen.
Da wäre noch die Politikerliste
Ergänzung: Interessant, was ein Lesertipp, mal nach .txt-Dateien zu suchen, da zu Tage fördert. Die Plattformbetreiber haben eine lange Liste mit 240 Landtagsabgeordneten, insbesondere von den Parteien SPD und Bündnis 90/Dien Grünen zusammen gestellt.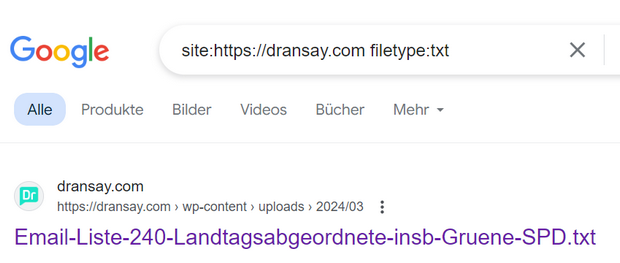
Diese Textdatei ist noch immer frei auf dransay.com abrufbar bzw. über die Suche verfügbar. Gut, die Listen sind i.d.R. über die Webseiten der jeweiligen Landtage abrufbar. Aber der Außenstehende fragt sich schon, warum sich da jemand eine Liste von Abgeordneten bestimmter Parteien in eine Textdatei „gießt“ und dann auch noch als notwendig erachtet, diese Datei frei auf seinen Server zu stellen?
Ähnliche Artikel:
Sicherheitsvorfälle März/April 2024 (Stand 9.4.2024)
Datenleck beim Bauhaus-Shop legte Bestellungen von Plus Card-Inhabern offen
Mögliche Schwachstelle bei Ticket-System der Koelnmesse aufgedeckt, gibt es einen 2. Modern Solutions-Fall?
Amtsgericht Jülich verurteilt Entdecker der Modern Solutions-Schwachstelle zu Geldstrafe (Jan. 2024)




Auf meine Anfrage hin nach meinen gespeicherten Daten nach DSGVO bekam ich diese Antwort vom Support:
Hallo,
wir entschuldigen uns an erster Stelle vielmals für die Umstände. Als Zweites möchten wir dich auf unseren Blogpost aufmerksam machen, in welchem wir den Vorfall schildern.
https://dransay.com/gesundheits-blog/rezept/datenleck/
Deine Daten werden, deinem Wunsch gemäß, umgehend gelöscht. Leider sind bei der Suchmaschine Bing (welche von DuckDuckGo genutzt wird) noch die alten Links indexiert (also in der Suche auffindbar). Zwar können die PDFs nicht mehr heruntergeladen werden, jedoch sind weiterhin der Name, Adresse und Geburtsdatum und in seltenen Fällen das verschriebene Medikament in den Suchergebnissen zu sehen. Wie im Blogpost beschrieben, tun wir alles in unserer Macht Stehende, um dies ebenfalls schnellstmöglich zu entfernen. Wie im Blogpost beschrieben, kannst du das ganze mitbeschleunigen, wenn du Bing über den angegebenen Link kontaktierst.
https://www.bing.com/webmaster/tools/eu-privacy-request?setlang=de
https://www.bing.com/toolbox/intermediatelogin/
So sehr wir deine Aufregung verstehen, bitten wir um dein Verständnis und hoffen auf deine Unterstützung. Selbstverständlich bist du das primäre Opfer, aber auch wir sind hier Opfer von Handlungen Dritter geworden. Das Ganze wurde bewusst von Dritten (höchstwahrscheinlich des ehemaligen Mitarbeiters, der ein illegales Konkurrenzunternehmen gegründet hat) öffentlich gemacht, um unser Unternehmen zu schädigen. Dabei waren ihnen eure Interessen und Rechte mehr als nur egal. Kein betroffener Patient würde doch das Ganze in die Öffentlichkeit treten und damit seine eigenen Daten publik machen. Um ihre Ziele zu erreichen, sind sie über Leichen gegangen und haben in Foren Anleitungen geteilt, wie die Daten auffindbar sind. Dabei gefährden sie das Unternehmen und die Jobs der gesamten Mitarbeiter.
Liebe Grüße
Dein Support-Team
Er kreidet dem angeblichen Konkurrenten an, die Konfigurationsfehler öffentlich gemacht zu haben.
Dank Steinsandeffekt würde die Webseite sehr viel bekannter, also das genaue Gegenteil eines Schadens.
Sie haben da 2 Fehler gemacht:
Den Zugriff nicht reglementiert und eine robots.txt vergessen haben.
duckduckgo ist eine Meta-Suchmaschine.
Sie sucht nicht selbst, sondern benutzt andere Suchmaschinen.
Das „Problem“ wäre hier nur Bing…
ist mir auch aufgefallen, dass man seit dem Datenleck keine alten Rezepte mehr herunterladen kann. Das ging bis zum 15.05 tadellos rückwirkend über Monate, das haben die erst umgestellt und war zum Zeitpunkt des Lecks definitiv „noch herunterladbar“.
Ich halte die Ex-Mitarbeiter Story für nicht völlig unplausibel, wobei besagte Konkurrenzseite eines/einer „Ghinel Cosma“ wie ein Dumy aussieht.
Das Gebelle in Richtung Suchmaschinen kann man aber wohl getrost ignorieren.
Korrekt!
Weil es kein illegales indexieren gibt:
https://developers.google.com/search/docs/crawling-indexing/block-indexing#meta-tag
Meta-tag oder Antwortkopfzeile geht beides. das ist getestet von mir, weil ich es in meinem privaten Server der meine Domain betreibt implementiert habe. bin Naturwissenschaftler und kein Programmierer. soviel dazu es wäre „schwer“.
Irgendwer wird drauf reinfallen haha, ja die pöhsen Suchmaschinen.
> Weil es kein illegales indexieren gibt: <
Unsinn; s. (1) S. 31 ff.
Für kommerzielle Indexierer sind die Verbote noch strikter. Zitat von S. 35: "Fraglich ist jedoch, welche rechtlichen Grenzen dem Web Scraping gesetzt sind und welche Vorgaben – speziell im Kontext der wissenschaftlichen Forschung – zu beachten sind. Hier gestaltet sich die Interessenlage anders als im Fall von kommerziellen Angeboten wie Vergleichsportalen, schließlich erfolgt das Scraping nicht aus rein pekuniären Motiven heraus. Vielmehr ist das Interesse des Datenbank- oder Webseitenanbieters mit dem (Allgemein-) Interesse an einer möglichst ungehinderten wissenschaftlichen Forschung in Einklang zu bringen."
(1) konsortswd.de/wp-content/uploads/RatSWD_Output4.6_BigData.pdf
Auf dem Index sein != scraping.
Deine domain kann auch komplett ohne seiteninhalt in den google resultaten auftauchen. (robots.txt beherzigt aber kein noindex und nofollow im meta tag / x header)
>Unsinn
>
Gut selbst erkannt, man muss nur den opt out machen. Illegal kann es ja nur sein wenn der Widerspruch ignoriert wird. Von daher hat dein Beitrag nichts bewiesen.
Es gibt eben mehr als einen Mechanismus, sondern 3 Methoden mit 4 Optionen.
X-Robots (header)
noindex (meta)
nofollow (meta)
robots.txt (veraltet und wird sogar von archive.org seit 2017 ignoriert)
bei letzerer seite kommt man erst vom index nach opt out per email. weiss ich alles weil ich bei archive.org das de-listing und löschen erbeten habe. (kann nur erfolgen bis zur registrierung, wenn jemand vor dir jemand die domain ohne widerspruch hatte bleibt der zeitabschnitt.)
ist nicht so schwarz-weiß wie du behauptest ;)
> Auf dem Index sein != scraping. <
Grundsätzlich zutreffend, in vorliegendem Kontext aber falsch. Die Angegriffenen erklärten (1): "Zwar können die PDFs nicht mehr heruntergeladen werden, jedoch sind weiterhin der Name, Adresse und Geburtsdatum und in seltenen Fällen das verschriebene Medikament in den Suchergebnissen zu sehen. "
Es liegt hier also gewissermassen 'Indexing mit Kollateralschaden Scraping' vor.
(1) https://www.borncity.com/blog/2024/05/16/cannabis-rezepte-datenleck-ceo-dr-jur-ansay-sucht-die-schuld-bei-anderen/#comment-181753
> Auf dem Index sein != scraping. <
Grundsätzlich zutreffend, in vorliegendem Falle aber falsch.
Die Angegriffenen erklärten (1): "Zwar können die PDFs nicht mehr heruntergeladen werden, jedoch sind weiterhin der Name, Adresse und Geburtsdatum und in seltenen Fällen das verschriebene Medikament in den Suchergebnissen zu sehen."
Es liegt also gewissermassen 'Indexing mit Kollateralschaden Scraping' vor.
(1) borncity.com/blog/2024/05/16/cannabis-rezepte-datenleck-ceo-dr-jur-ansay-sucht-die-schuld-bei-anderen/#comment-181753
Erst dachte ich, wir hätten noch den 1. April. Ist schon echt harter Tobak. Da stellt ein Anbieter sensible Daten offen ins Netz und dann solche eine Reaktion. Bin mal gespannt, ob das irgendwelche Konsequenzen für den Betreiber hat (z.B. Bußgeld). Das Fehler passieren können ist klar, aber die Reaktion zeugt nicht gerade von Einsicht.
Was fällt mir da als erstes ein?
Der Wahlspruch von Lindner:
„Digitalisierung first, Bedenken second.“
Macht ruhig weiter so :D
1.
[Born:] dass Suchmaschinen-Crawler über eine robots.txt ausgeschlossen werden können,
Aus WP: A robots.txt has no enforcement mechanism in law or in technical protocol, despite widespread compliance by bot operators.
2.
[Ansay:] gecrawlt und indexiert hat. Das war technisch möglich aufgrund eines zu geringen Sicherheitsniveaus, das unbemerkt verursacht wurde von dem Ex-Mitarbeiter Florian K.,
Dem müsste man einmal auf den Grund gehen. Meine Vermutung (unter der Annahme dass Apache httpd vorliegt): Eine robots.txt spielt überhaupt keine Rolle. Stattdessen: Jemand hat die "DirectoryIndex Directive" (1) manipuliert und so Verzeichnisinhalte (Directory Listings) exponiert. Und/oder: Jemand hat die "Require file-group" Directive (2) manipuliert/deaktiviert/gelöscht und so den vormaligen Schutz durch "filesystem permissions" beseitigt.
(1) httpd.apache.org/docs/2.4/mod/mod_dir.html
(2) httpd.apache.org/docs/2.4/mod/mod_authz_groupfile.html
Selbst dann könnte es nicht passieren, wenn der Rest korrekt konfiguriert wurde, wie ich oben verlinkt habe.
>robots.txt
In 2024? So was macht man mit meta-tags und in Antwortkopfzeilen wie dem X-Robots-Tag.
Gibt so viele Firmen die in der robots.txt die ganzen interessanten Pfade selbst leaken.. weil sie von den vorherigen 2 Optionen nix verstehen.
> Selbst dann könnte es nicht passieren, wenn der Rest korrekt konfiguriert wurde, wie ich oben verlinkt habe. <
Unsinn, es gilt weiterhin (aus WP): "… has no enforcement mechanism … in technical protocol, despite widespread compliance by bot operators."
bitte oben lesen, habe dir jetzt schon 1mal geantwortet
Meine Oma hätte jetzt gesagt, der redet sich um Kopf und Kragen.
Was für ein Geblubber in dieser Stellungnahme.
Ja ja, solange die Bots und Crawler schön dafür sorgen, dass seine Internetpräsenz ganz oben in den Suchergebnissen auftaucht, ist ja alles takko.
Bin mal echt gespannt, wer/was nun wirklich schuld ist an dem Leak.
Eigentlich wäre folgende Reaktion seitens Bings nur fair: Da der Betreiber seine User mit Nachdruck auffordert, Bing mit Löschanträgen zu bombardieren, einfach die komplette Domain aus der Suche entfernen. Bing ist doch eh voll pöse. Das müsste doch in seinem Interesse sein. Oder etwa doch nicht…?
So grundsätzlich bleibt die Verantwortung natürich beim Betreiber, die kann man nicht einfach so irgendwohin abschieben. Da es Mittel und Wege gibt, auf die Daten in der Suchmaschine einzuwirken, sollten die auch gegangen werden. Dahin gekommen sind die ja auch nur, weil sie letztlich frei verfügbar waren.
Grundsätzlich sollten Anbieter sich der Brisanz des Umstands bewusst sein, dass ein einziger Fehler die Daten auch in Ecken des Netzes verschlagen kann, aus denen man die nicht mehr rausextrahieren kann. Der Schaden kann also jederzeit absolut sein und dem sollten die eigenen Maßnahmen von Anfang an entsprechen. Je länger man dann auch noch zögert, desto vorschubleistender ist es für einen nicht mehr aufzuhaltenden Schaden.
Unabhängig davon fände ich die gerichtliche Beantwortung der Frage interessant, ob es tatsächlich zulässig ist, Daten aus allen irgendwie erreichbaren Bereichen des Internets zu speichern, verarbeiten und prominent zu veröffentlichen. Womit sie ja trotz Löschmöglichkeit an prominenter Stelle für einen ungebremsten Missbrauch verfügbar gemacht werden.
Vielleicht gibt es ja auch schon ein Urteil, das das Kunstsück der erforderlichen Interessenabwägung einer Verarbeitung öffentlicher Daten wegen berechtigter Interessen beleuchtet, wenn es sich bei den Daten um „einfach alle irgendwie erreichbaren Daten“ handelt.
Je nachdem welche Daten das sind (z.B. Ethnie, politische Weltanschauung usw), fände ich dann auch die Argumentation interessant, woraus sich ergeben soll, dass die Verarbeitung sich auf personenbezogene Daten beziehen soll, „die die betroffene Person offensichtlich öffentlich gemacht hat“, wenn man durch alle möglichen Unterverzeichnisse irgendwelcher Seiten crawlt und dort eine Datensammlung beliebig sensibler Daten findet.
Die allgemeine Überzeugung, dass crawler einfach alles dürfen, was sie eben können und man ihnen nicht explizit verboten hat, teile ich irgendwie nicht. Kann ich auch nicht aus der DSGVO rauslesen.
Aber seisdrum.
Ob die Sachen bei archive.org noch abrufbar sind?
gefunden habe ich bei einer kurzen Suche nichts mehr
Die „Stellungnahme“ ist ja an Peinlichkeit nicht zu übertreffen. Wer hat das formuliert? Die Schreibweise, ganz ab von diversen Fehlern… ein seriöses Unternehmen scheint das nicht zu sein.
Und helfen sollen die betroffenen Kunden dann auch noch? Ich komme aus dem Lachen nicht mehr raus. :-D
Unter Jobs sucht man u. a. schon einen CEO und Web Developer, gerade der scheint dringend notwendig zu sein.
„ein seriöses Unternehmen scheint das nicht zu sein.“
Ist es objektiv nicht. Dieser Herr Rechtsanwalt Dr. Ansay ist schon seit Jahren für seine dubiosn Geschäftspraktiken bekannt. Seine 80-jährige Mutter, deren Namen er lange für die Vortäuschung einer angeblichen medizinischen Kompetenz missbraucht hat, hat inzwischen aufgrund dessen ihre Zulassung verloren.
Ein kleiner Auszug:
https://www.businessinsider.de/gruenderszene/health/au-schein-hamburg-can-ansay/
https://www.zeit.de/2022/01/can-ansay-corona-test-internet-verbot-unternehmer
https://www.t-online.de/region/hamburg/id_100088936/corona-betrug-schillernder-tech-millionaer-in-hamburg-angeklagt.html
https://www.apotheke-adhoc.de/nachrichten/detail/panorama/frau-dr-ansay-verliert-ihre-approbation/
Was ist das?
https://dransay.com/wp-content/uploads/2022/06/Arret-Maladie-DrAnsay.pdf
LOL, ’ne französische Krankmeldung?
(https://www.service-public.fr/particuliers/vosdroits/R1458)
Von Emmanuel Macron? WTF …
Da hat sich wohl jemand ein Späßchen erlaubt. Laut Google-Suche, auch in streetmap verifiziert, ist dort in der 198 Av. de France, 75013 Paris, wo der praktizierende Arzt in dem Formular die Adresse hat, ein Wework Coworking-Space. Da glaub ich jetzt nicht so dran…
https://www.google.de/maps/@48.8360308,2.37169,3a,53y,84.45h,93.96t/data=!3m7!1e1!3m5!1sLYcLzfo-ofDukAxiYC9ZPw!2e0!6shttps:%2F%2Fstreetviewpixels-pa.googleapis.com%2Fv1%2Fthumbnail%3Fpanoid%3DLYcLzfo-ofDukAxiYC9ZPw%26cb_client%3Dsearch.gws-prod.gps%26w%3D86%26h%3D86%26yaw%3D75.84737%26pitch%3D0%26thumbfov%3D100!7i16384!8i8192?entry=ttu
https://www.wework.com/de-DE/buildings/198-avenue-de-france–paris
Aber, echt jetzt? Arbeiten die Franzosen immer noch mit DIESEN altertümlichen Formularen bei Krankmeldungen? Hab vor ~27 Jahren mal 1 Jahr in Frankreich gearbeitet, und da gab es das schon so oder ganz ähnlich…
Es regnet nicht nur unentwegt, nein es leckt und fließt ja überall …
https://www.heise.de/news/Nach-Ransomwareangriff-Daten-von-Polizei-Hochschule-in-Hessen-abgeflossen-9721818.html
Herzliche Grüße Ihre
NIS2